User's Manual - version: 0.3
KEYVALUE
Figure 5. Console logger shows key-value pairs in data set Triangle.
[Debug ] DataSet: Triangle
Size : 4
Key #1: Base
Value #1: [Single] 2
Key #2: Height
Value #2: [Single] 3
Key #3: IsRegular
Value #3: [Single] 0
Key #4: Processor
Value #4: [Single] PolygonFor a text to define a key, it is necessary but not sufficient that:
excluding trailing spaces it ends with " ="
(space + equal sign); and
excluding the ending "=", it contains a non space
character.
KeyValue replaces the last "=" (equal sign) by "
" (space) and, from the result, removes leading and trailing
spaces. What remains is the key. For instance, all data sets in sheet
The KEYVALUE function contain a key called
Processor defined by the text "Processor
=".
The conditions above are not sufficient to define a key since the
patterns mentioned earlier also play a role in this matter. For instance,
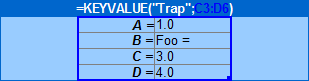
in data set Trap of sheet Key-value
patterns , "Foo =" does not define a key
Foo.
Actually, it assigns the value "Foo =" to key
B as you can verify in the console after recalculating
B2.
Figure 7. Console shows that "Foo =" is the value assigned
to key B.
[Debug ] DataSet: Trap
Size : 4
Key #1: A
Value #1: [Single] 1
Key #2: B
Value #2: [Single] Foo =
Key #3: C
Value #3: [Single] 3
Key #4: D
Value #4: [Single] 4The following sections explain the patterns and clarify this point.
This pattern is composed by two parts: A single containing a text defining a key (i.e. verifying the necessary conditions) followed by either a single, vector or matrix, which will be the associated value. Those three possibilities are shown on the sheet Key-value patterns.
There are two cases of this pattern. The first (the transpose of the second) is composed by a column vector followed by a matrix such that
they have the same number of rows; and
the vector contains only keys (i.e. all cells contain text verifying the necessary conditions).
Furthermore, for each key in the vector, the corresponding row in the matrix defines a vector which is the value associated to the key.
There are two cases of this pattern. The first (the transpose of the second) is composed by a matrix such that
it has at least two columns;
the first column contains only keys (i.e. all cells contain text verifying the necessary conditions); and
the first cell of second column is not a key (i.e. it does not contain text verifying the necessary conditions ).
Furthermore, for each key in the first column, the remaining cells on the same row define a vector which is the value associated to the key.
Useful for tables, this pattern is made by one matrix M = M(i, j) , for i = 0, ..., m-1 and j = 0, ..., n-1 (with m>2 and n>2). In M we find three key-value pairs: row, column and table. There are two variants of this pattern:
The row key is in M(1, 0) and its value is the column vector M(i, 0) for i = 2, ..., m-1. The column key is in M(0, 1) and its value is the row vector M(0, j) for j = 2, ..., n-1. Finally, the table key is in M(0,0) and its value is the sub-matrix M(i, j) for i = 2, ..., m-1 and j = 2, ..., n-1.
The row key is in M(2, 0) and its value is the column vector M(i, 1) for i = 2, ..., m-1. The column key is in M(0, 2) and its value is the row vector M(1, j) for j = 2, ..., n-1. Table key and value are as in Format 1. This variant is more aestheticly pleasant when some cells are merged together as show in data set Table #2 (merged) in Figure 11.